
Hugging Face stands as the GitHub of artificial intelligence. The platform hosts over 1 million models, datasets, and applications for machine learning.
Developers, researchers, and companies rely on Hugging Face resources for AI projects. Tech giants like Apple, Google, Microsoft, and Meta actively use the platform.
What exactly does Hugging Face offer? How do you use it? Which projects benefit most from it?
This guide covers all platform features, use cases, and getting started steps in detail.
What Is Hugging Face?
Hugging Face is an open-source platform and community for machine learning models. French entrepreneurs founded the company in New York City in 2016.
Founders Clément Delangue, Julien Chaumond, and Thomas Wolf initially developed a chatbot application. They targeted teenagers with an interactive conversational bot.
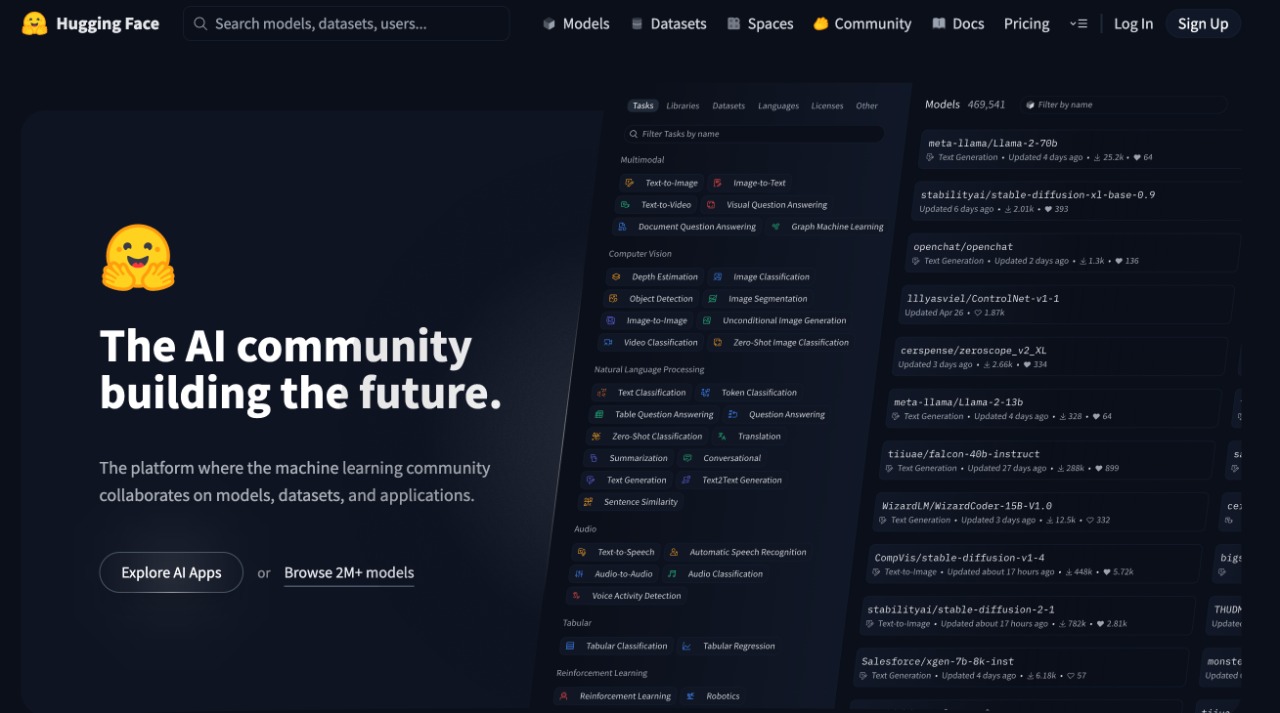
After open-sourcing the chatbot model, something unexpected happened. The developer community showed massive interest in the model. The company pivoted to become a machine learning platform.
The platform takes its name from the 🤗 hugging face emoji. Founders aimed to become the first company to go public with an emoji ticker symbol. The community embraced the name and it became part of the brand identity.
Hugging Face’s core mission is democratizing artificial intelligence and making it accessible to everyone. Models requiring millions of dollars in compute costs are available for free on the platform.
Using pre-trained models instead of training from scratch saves enormous time. Fine-tuning approaches dramatically reduce costs for custom applications.
Platform Statistics
Hugging Face completed a $235 million Series D funding round in 2023. The company reached a $4.5 billion valuation.
Total funding exceeded $396 million. Nvidia, Google, Salesforce, and Amazon are among the investors.
Daily installations surpass 3 million. Total installations exceeded 1.2 billion. The Transformers library collected over 150,000 stars on GitHub.
The platform receives 28 million monthly visits. Male users make up 75% while females comprise 25%. The 25-34 age group represents 37% of the user base.
Over 10,000 companies use Hugging Face infrastructure. Intel, Pfizer, Bloomberg, and eBay are among them. More than 1,000 active paying enterprise customers exist.
Annual recurring revenue reached $70 million in 2023. Revenue grew 367% compared to the previous year. Consulting contracts with Nvidia, Amazon, and Microsoft drive significant revenue.
Core Components
The Hugging Face ecosystem consists of four main components working together. Each component addresses different needs.
Hugging Face Hub
The Hub serves as the central repository for models and datasets. Users can discover, test, and integrate models into their projects.
What GitHub is for code sharing, Hugging Face Hub is for AI models. Researchers publish their work here. Developers access ready-to-use models.
The platform hosts over 1 million models. Dataset count exceeds 250,000 and application count surpasses 250,000. Numbers grow daily.
Every model comes with a “model card.” The card explains how the model works and which tasks it suits. Training data, performance metrics, and usage examples are included.
Models are organized into categories. Text, image, audio, and multimodal filters exist. Sorting by popularity, downloads, and recency is available.
Transformers Library
Transformers is Hugging Face’s most popular open-source library. It became the standard for natural language processing.
The library supports over 300 model architectures. BERT, GPT, LLaMA, Qwen, and Mistral are included. An average of 3 new architectures get added weekly.
Transformers v5 released in December 2025 brought major changes. PyTorch became the primary framework. TensorFlow and Flax support is being sunset.
The library supports text, image, audio, and multimodal tasks. A single API works with different models. Code consistency is maintained.
Transformers works with training frameworks seamlessly. Axolotl, Unsloth, DeepSpeed, and PyTorch-Lightning are supported. Inference engines vLLM, SGLang, and TGI integrate well.
Datasets Library
The Datasets library enables loading datasets with a single line of code. Apache Arrow format allows working with large data without memory constraints.
The platform offers text datasets in 467 languages. Image, audio, and video datasets are also available. Special collections exist for low-resource languages.
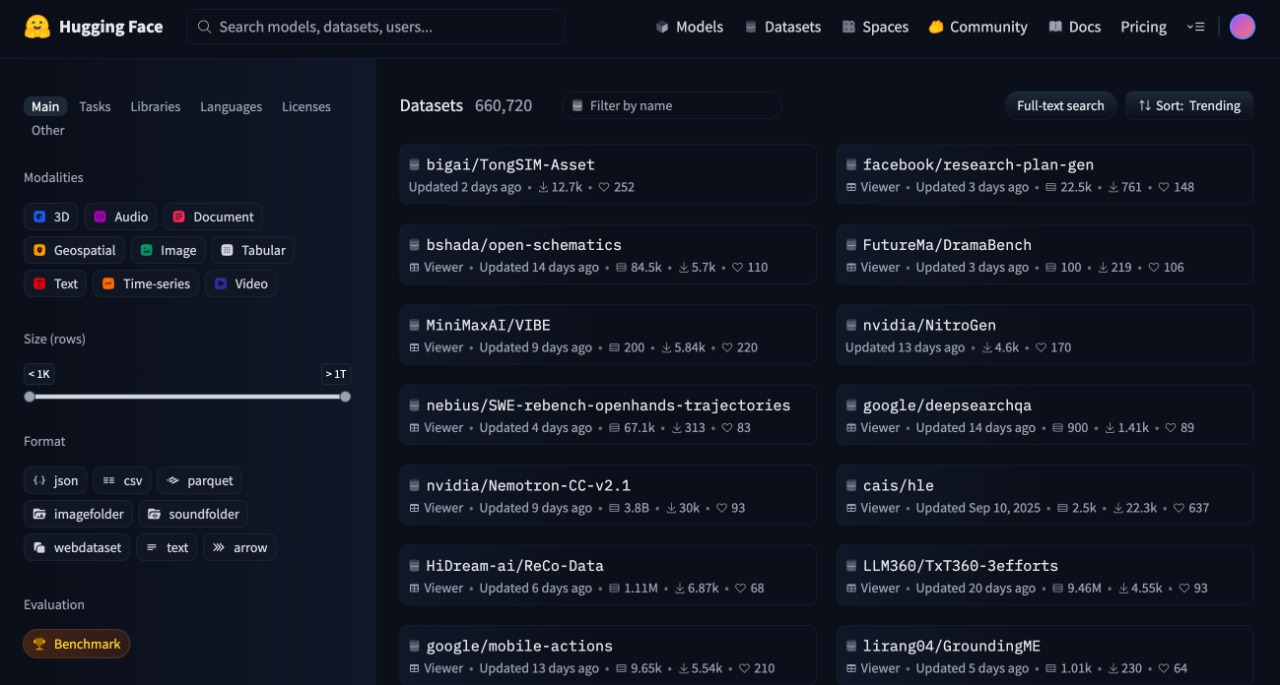
CSV, JSON, Parquet, HDF5, and more formats are supported. Data works with PyTorch, TensorFlow, JAX, and NumPy.
Streaming feature enables using large datasets without downloading. Disk space is saved. Processing speed increases.
Data preprocessing functions are built-in. Map, filter, and shuffle operations apply easily. Batch encoding and padding happen automatically.
Spaces
Spaces serves as the demo environment for AI applications. Users can test models directly in browsers. No installation required.
Gradio and Streamlit integration exists. Anyone with Python knowledge can create demos. Interface design is simplified.
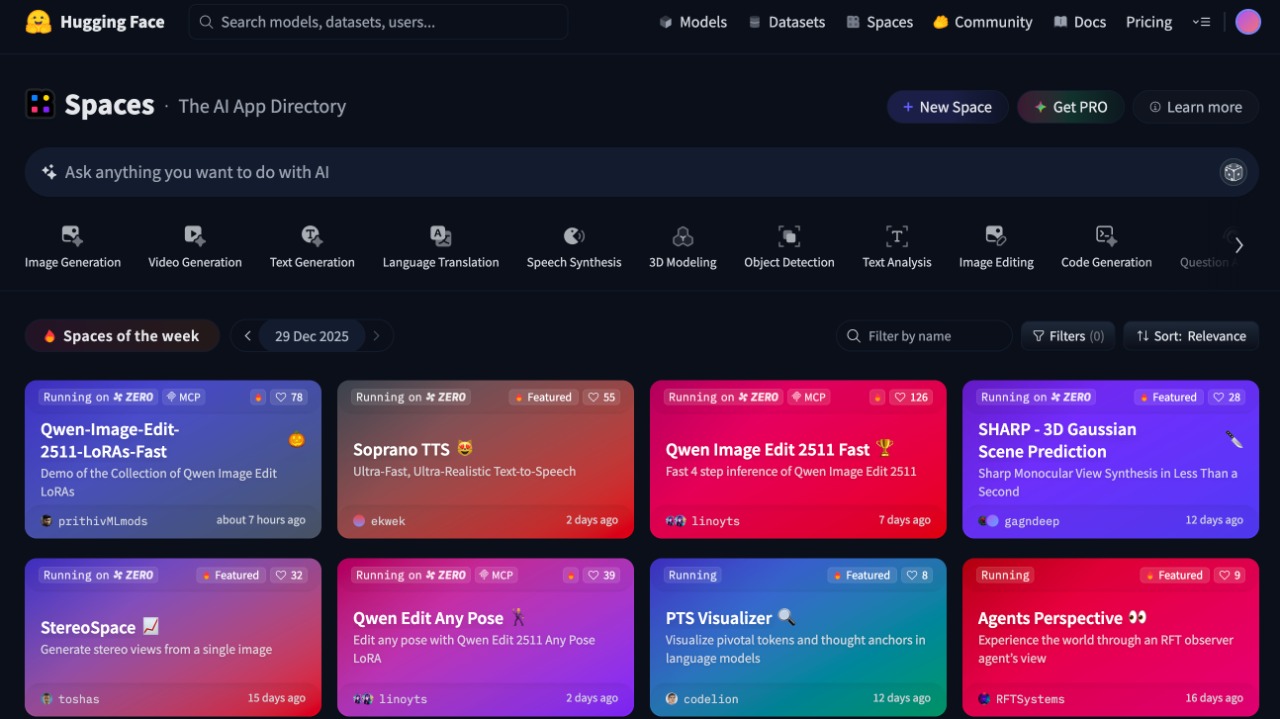
Developers can create their own demo pages. Sharing with the community becomes easy. Feedback collection speeds up.
GPU-powered Spaces are offered for a fee. Required for compute-intensive demos. Pricing varies by usage.
Supported Tasks
Hugging Face covers a wide range of tasks. Specialized models exist for each area.
Natural Language Processing (NLP)
NLP is where Hugging Face excels most. The platform was born and grew in this area.
Text classification models can detect spam, analyze sentiment, and determine topics. BERT-based models achieve high accuracy in these tasks.
Question answering systems can extract information from documents. Extractive and generative approaches are supported. Customer service chatbots use these models.
Text summarization models can condense long content. News articles, research reports, and meeting notes can be summarized.
Translation models support over 100 language pairs. Meta’s NLLB model can translate in 200 languages. Special efforts exist for low-resource languages.
GPT-based models are available for text generation. Open-source alternatives to closed-source options like ChatGPT and Claude are offered. LLaMA, Mistral, and Qwen are popular choices.
Named entity recognition (NER) detects person, place, and organization names in text. It forms the foundation of information extraction systems.
Computer Vision
Hugging Face is growing rapidly in image processing. The Timm library acquisition strengthened this area.
Image classification models can recognize objects in photos. ResNet, ViT, and ConvNeXT architectures are supported. Models trained on ImageNet are ready.
Object detection models locate objects in images. YOLO, DETR, and Faster R-CNN are available. Autonomous vehicles and security systems use these models.
Image segmentation performs pixel-level classification. Critical for medical imaging and satellite photo analysis. SAM (Segment Anything Model) revolutionized this area.
Stable Diffusion models for image generation are hosted on the platform. Open-source options among best AI image generators are available for free.
Audio Processing
Important models in audio are available on Hugging Face. Speech technologies are advancing rapidly.
Automatic speech recognition (ASR) converts speech to text. OpenAI’s Whisper model can transcribe in 99 languages. Used for podcast and video captioning.
Text-to-speech (TTS) produces natural audio output. Bark and XTTS models synthesize human-like voices. Important for voice assistants and accessibility applications.
Audio classification can recognize environmental sounds. Music genre detection, emotion analysis, and speaker identification are possible.
Multimodal Applications
Models combining multiple modalities are rising. Image and text can be processed together.
Image captioning models generate text describing photos. Provides accessibility for visually impaired users. Social media and e-commerce platforms use them.
Visual question answering responds to questions about images. Questions like “How many people are in this photo?” can be answered.
Video analysis models are also being added to the platform. Video summarization and content moderation are possible.
| Task Category | Model Count | Popular Models |
|---|---|---|
| Natural Language Processing | 500000+ | BERT GPT LLaMA |
| Computer Vision | 200000+ | ViT ResNet YOLO |
| Audio Processing | 50000+ | Whisper Bark Wav2Vec |
| Multimodal | 100000+ | CLIP LLaVA BLIP |
How to Use Hugging Face
Using Hugging Face involves a few simple steps. Both web interface and programmatic access are available.
Creating an Account
Visit huggingface.co to create a free account. Registration via email or GitHub account is possible.
Profile settings are configured after registration. Username and bio are added. Profile photo can be uploaded.
Organizations can be created and team members invited. Organization structure is recommended for enterprise projects.
API token is generated from profile settings. Token is required for programmatic access. Read and write permissions can be granted separately.
Using the Web Interface
The web interface is the easiest starting point. Models can be tested without writing code.
Search for the desired model on the Hub. Filtering options make narrowing down easy. Review the model card to check suitability.
Models can be tested directly from the “Inference API” section. Text input is provided and output is displayed. Ideal for quick experimentation.
Interactive demos can be used through Spaces. Complex models are experienced through visual interfaces.
Using Python
Python is preferred for professional use. Start by installing the Transformers library.
pip install transformersModels can be used with just a few lines of code using the Pipeline API:
from transformers import pipeline
generator = pipeline("text-generation", model="Qwen/Qwen2.5-1.5B")
result = generator("The future of artificial intelligence")Models are automatically downloaded and cached. No re-downloading needed for reuse. Disk space is used efficiently.
Pipeline types vary for different tasks. Sentiment analysis, summarization, and translation tasks are supported.
# Sentiment analysis
classifier = pipeline("sentiment-analysis")
result = classifier("This product is amazing!")
# Summarization
summarizer = pipeline("summarization")
summary = summarizer(long_text, max_length=100)Fine-tuning
Pre-trained models can be fine-tuned with your own dataset. The Trainer API simplifies the process.
Fine-tuning should be preferred over training from scratch. Time and cost savings are achieved. Good results come from less data.
from transformers import Trainer, TrainingArguments
training_args = TrainingArguments(
output_dir="./results",
num_train_epochs=3,
per_device_train_batch_size=8
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset
)
trainer.train()The PEFT (Parameter-Efficient Fine-Tuning) library enables low resource usage. LoRA and QLoRA techniques make training large models on small GPUs possible.
Popular Models
Some models stand out on Hugging Face. Download counts and community interest determine these.
Large Language Models
The LLaMA series is developed by Meta. Most popular choice among open-source LLMs. LLaMA 3.1 405B is the largest version.
The Qwen series comes from Alibaba. Stands out with multilingual capabilities. Qwen2.5 became the most downloaded text LLM.
Mistral models come from the French AI company. Offers high performance despite small size. Mistral 7B is ideal for efficiency-focused projects.
DeepSeek offers a powerful alternative from China. Shows high success in coding and mathematics.
Image Models
Stable Diffusion generates images from text descriptions. SDXL and SD3 are the latest versions. Widely used in art and design projects.
CLIP represents images and text in a shared space. Forms the foundation for visual search and classification.
SAM (Segment Anything) can segment any object. Developed by Meta AI. Revolutionized image editing applications.
Audio Models
Whisper is OpenAI’s speech recognition model. Can transcribe in 99 languages. Released as open source.
Bark generates realistic speech from text. Different languages and accents are supported. Emotion and intonation control is possible.
| Model | Developer | Parameters | Use Case |
|---|---|---|---|
| LLaMA 3.1 | Meta | 405B | General purpose LLM |
| Qwen2.5 | Alibaba | 72B | Multilingual applications |
| Mistral | Mistral AI | 7B | Efficient inference |
| Stable Diffusion XL | Stability AI | 3.5B | Image generation |
| Whisper | OpenAI | 1.5B | Speech recognition |
Hugging Face Advantages and Disadvantages
Like every platform, Hugging Face has strengths and weaknesses.
- Over 1 million free models
- Active developer community
- Comprehensive documentation
- PyTorch and TensorFlow support
- Easy fine-tuning capability
- Enterprise-grade security
- AWS and Azure integration
- Large models require high compute
- Some models have license restrictions
- Advanced features are paid
- Model quality can vary
Pricing
Hugging Face uses a freemium model. Basic features are available for free.
Free Plan
Unlimited public model and dataset hosting exists. CPU-powered demos can be created on Spaces.
Community support and documentation access are provided. Inference API gives limited usage rights.
Pro Plan
Advanced features are offered for $9 per month. Private dataset viewing and inference features unlock.
Early access program inclusion is available. New features are offered to Pro users first.
Enterprise Solutions
Custom model training and deployment services are provided to enterprise customers. Private Hugging Face Hub setup is available.
SSO integration and advanced security features exist. Custom SLA and priority support are provided.
Inference Endpoints allow creating custom endpoints. Auto-scaling and high availability are offered.
| Plan | Price | Features |
|---|---|---|
| Free | $0 | Public models and limited inference |
| Pro | $9/month | Advanced inference and early access |
| Enterprise | Custom pricing | Full customization and priority support |
Who Uses Hugging Face?
Tech giants use Hugging Face models in production environments.
Google, Meta, and Microsoft prefer the Transformers library in research projects. Apple benefits from the platform for NLP applications.
Bloomberg uses Hugging Face models for financial text analysis. Intel and AMD collaborate for hardware optimizations.
Academic usage is also widespread. Stanford, MIT, and Oxford researchers share models. Most published papers include Hugging Face references.
Startups prefer the platform for rapid prototyping. Ready models shorten development time. MVP to production transition accelerates.
In healthcare, Pfizer and other pharmaceutical companies use it for research. Medical text analysis and drug discovery work is conducted.
Alternatives and Comparison
Some alternatives to Hugging Face exist. Each has different strengths.
TensorFlow Hub is Google’s model repository. Offers deep integration with TensorFlow ecosystem. However, model diversity falls behind Hugging Face.
PyTorch Hub is the official repository for PyTorch models. Hosts research-focused models. Community support is more limited.
Model Zoo offers models for different frameworks. Scattered structure makes usage difficult.
Replicate offers API for model deployment. An inference-focused platform. Does not support model training.
Companies like OpenAI and Anthropic offer closed-source models. Grok and other alternatives may suit different use cases.
Future Plans
Hugging Face continues to grow constantly. New areas are being explored.
Entering Robotics
Hugging Face acquired Pollen Robotics in April 2025. The French robotics startup was developing humanoid robots.
The acquisition aims to bring AI models to the physical world. Expansion into robotics, automotive, and IoT is planned.
The LeRobot project offers open-source tools for robotics. Simulation and real-world training are supported.
Edge AI
Running AI on mobile and embedded devices is gaining importance. The Optimum library provides model optimization.
Quantization and pruning techniques reduce model size. ONNX conversion enables running on different platforms.
AI Agents
Hugging Face developed its own AI agent. Open Computer Agent can perform tasks in browsers.
The Smolagents library simplifies agent development. Offers alternatives to coding agents like Claude Code.
Getting Started Tips
Recommendations for those new to Hugging Face:
- Test models in the web interface first
- Start with small models then scale up
- Read model cards carefully
- Follow community forums
- Complete official courses
- Use Colab for GPU access
Conclusion
Hugging Face fundamentally changed the AI development process. AI projects that previously required large budgets are now accessible to everyone.
The platform continues to strengthen its position as the GitHub of machine learning. Open-source approach accelerates innovation. Community contributions enrich the ecosystem.
Over 1 million models, comprehensive documentation, and active community support are offered. Resources exist for every user from beginner to advanced level.
You can start exploring Hugging Face resources for your AI projects today. Strengthen your projects by using them together with tools among the best AI apps.
Source: Hugging Face | Wikipedia | GitHub
